link:
我使用的是eclipse 3.7,开始使用的插件是hadoop-0.20.2文件夹下/contrib下的eclipse插件hadoop-0.20.2-eclipse-plugin.jar,配置完eclipse后,出现了run on hadoop没反应,后来看了网上一篇文章:
http://hi.baidu.com/laxinicer/blog/item/fbaddaf58bdae63fbc3109a0.html
下载了hadoop-0.20.3-dev-eclipse-plugin.jar插件,改名为hadoop-0.20.2-eclipse-plugin.jar,然后放到exlipse的plugin文件夹下,重新配置mapreduce location,最后run on hadoop成功了,伪分布模式下!!!
mark 一下
eclipse下配置hadoop步骤:
1.将 hadoop-0.20.3-dev-eclipse-plugin.jar改名为hadoop-0.20.2-eclipse-plugin.jar复制 到 eclipse安装目录/plugins/ 下。
2.重启eclipse,配置hadoop installation directory。
如果安装插件成功,打开Window-->Preferens,你会发现Hadoop Map/Reduce选项,在这个选项里你需要配置Hadoop installation directory。配置完成后退出。3.配置Map/Reduce Locations。
在Window-->Show View中打开Map/Reduce Locations。在Map/Reduce Locations中新建一个Hadoop Location。在这个View中,右键-->New Hadoop Location。在弹出的对话框中你需要配置Location name,如myubuntu,还有Map/Reduce Master和DFS Master。这里面的Host、Port分别为mapred-site.xml、core-site.xml中配置的地址及端口。
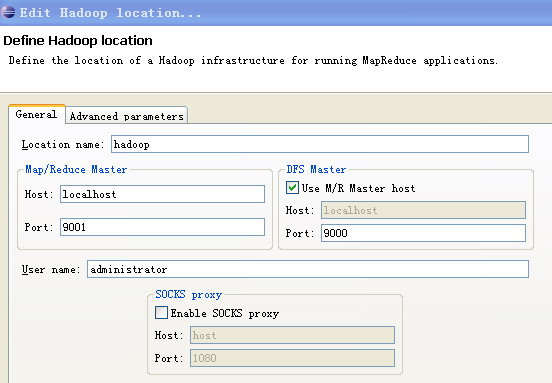
4.新建项目。
File-->New-->Other-->Map/Reduce Project项目名可以随便取,如hadoop-test。复制 hadoop安装目录/src/example/org/apache/hadoop/example/WordCount.java到刚才新建的项目下面。5.上传模拟数据文件夹。为了运行程序,我们需要一个输入的文件夹,和输出的文件夹。输出文件夹,在程序运行完成后会自动生成。我们需要给程序一个输入文件夹。在当前目录(如hadoop安装目录)下新建文件夹input,并在文件夹下新建两个文件file01、file02,这两个文件内容分别如下:file01:Hello World Bye World
file02:Hello Hadoop Goodbye Hadoop6.运行项目。
a..在新建的项目hadoop-test,点击WordCount.java,右键-->Run As-->Run Configurationsb..在弹出的Run Configurations对话框中,点Java Application,右键-->New,这时会新建一个application名为WordCountc..配置运行参数,点Arguments,在Program arguments中输入“你要传给程序的输入文件夹和你要求程序将计算结果保存的文件夹”,如- hdfs://localhost:9000/user/Administrator/input01 hdfs://localhost:9000/user/Administrator/output01
- hdfs://localhost:9000/user/Administrator/input01 hdfs://localhost:9000/user/Administrator/output01
7.点击Run on hadoop,运行程序。
8.等运行结束后,可以在终端中用命令bin/hadoop fs -cat output01/* 查看生成的文件内容。
eclipse控制台输出信息:
12/03/03 09:27:42 WARN conf.Configuration: DEPRECATED: hadoop-site.xml found in the classpath. Usage of hadoop-site.xml is deprecated. Instead use core-site.xml, mapred-site.xml and hdfs-site.xml to override properties of core-default.xml, mapred-default.xml and hdfs-default.xml respectively
12/03/03 09:27:42 INFO input.FileInputFormat: Total input paths to process : 212/03/03 09:27:43 INFO mapred.JobClient: Running job: job_201203030918_000412/03/03 09:27:44 INFO mapred.JobClient: map 0% reduce 0%12/03/03 09:27:53 INFO mapred.JobClient: map 100% reduce 0%12/03/03 09:28:05 INFO mapred.JobClient: map 100% reduce 100%12/03/03 09:28:07 INFO mapred.JobClient: Job complete: job_201203030918_000412/03/03 09:28:07 INFO mapred.JobClient: Counters: 1712/03/03 09:28:07 INFO mapred.JobClient: Job Counters 12/03/03 09:28:07 INFO mapred.JobClient: Launched reduce tasks=112/03/03 09:28:07 INFO mapred.JobClient: Launched map tasks=212/03/03 09:28:07 INFO mapred.JobClient: Data-local map tasks=212/03/03 09:28:07 INFO mapred.JobClient: FileSystemCounters12/03/03 09:28:07 INFO mapred.JobClient: FILE_BYTES_READ=11712/03/03 09:28:07 INFO mapred.JobClient: HDFS_BYTES_READ=7012/03/03 09:28:07 INFO mapred.JobClient: FILE_BYTES_WRITTEN=30412/03/03 09:28:07 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=5812/03/03 09:28:07 INFO mapred.JobClient: Map-Reduce Framework12/03/03 09:28:07 INFO mapred.JobClient: Reduce input groups=712/03/03 09:28:07 INFO mapred.JobClient: Combine output records=912/03/03 09:28:07 INFO mapred.JobClient: Map input records=212/03/03 09:28:07 INFO mapred.JobClient: Reduce shuffle bytes=12312/03/03 09:28:07 INFO mapred.JobClient: Reduce output records=712/03/03 09:28:07 INFO mapred.JobClient: Spilled Records=1812/03/03 09:28:07 INFO mapred.JobClient: Map output bytes=11412/03/03 09:28:07 INFO mapred.JobClient: Combine input records=1112/03/03 09:28:07 INFO mapred.JobClient: Map output records=1112/03/03 09:28:07 INFO mapred.JobClient: Reduce input records=9